SQLcl: Make NULLs “visible”
Posted: March 12, 2017 Filed under: Oracle, SQLcl | Tags: Oracle, SQLcl Leave a commentOne of the nice features in SQL Developer is to be able to define a value to replace NULLs (for display purpose only) in the data grids. Jeff Smith has a blog post about it in case you are interested.
You can achieve something similar in your SQLcl session by using set null some_string.
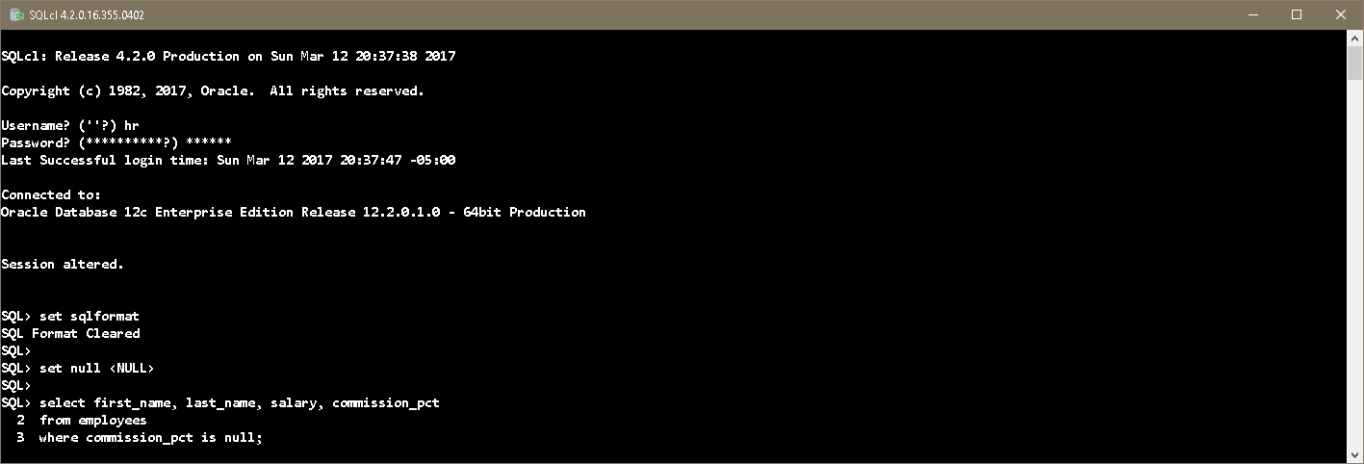
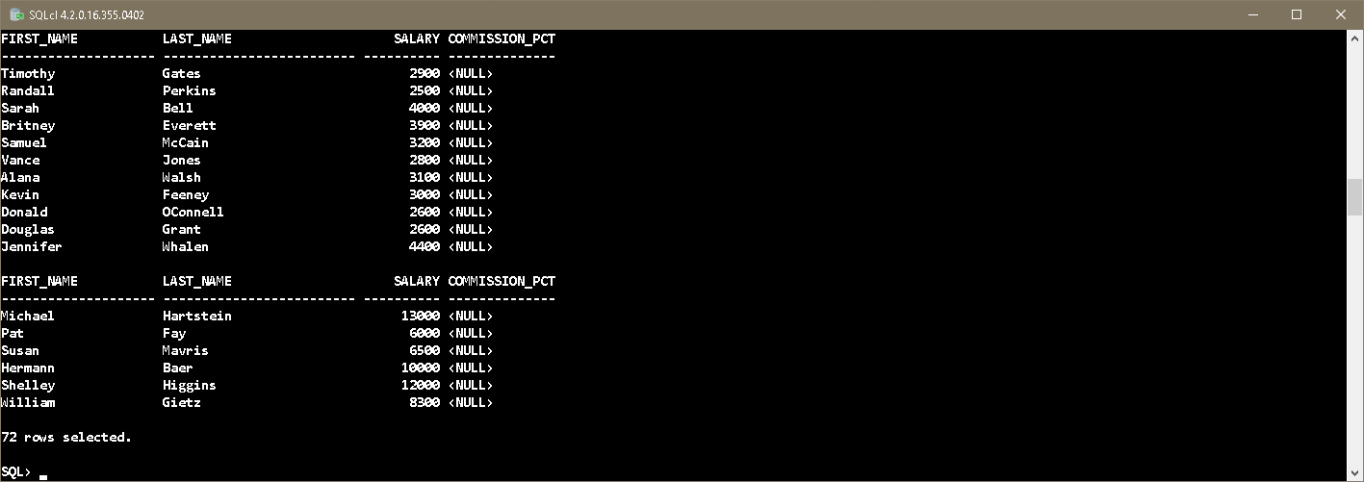
And here is the output from a query after setting the system variable.
Which SQLcl build am I running?
Posted: November 20, 2016 Filed under: Oracle, SQLcl | Tags: Oracle, SQLcl 2 CommentsThis is something I discovered a few minutes ago by pure coincidence and it’s not documented as far as I know.
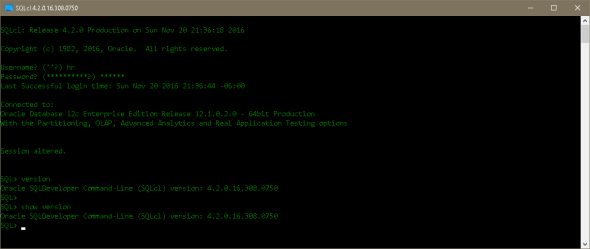
You can enter version or show version and it will tell you the exact SQLcl build that you’re executing.
Presenting at Oracle Open World 2016
Posted: August 28, 2016 Filed under: Open World, SQLcl | Tags: Open World, SQLcl Leave a comment
Just a short post to announce that I’ll be presenting an User Group Forum session. Thanks ODTUG!
SQLcl: A Modern Command Line Interface to the Oracle Database [UGF5641]
“In this session learn about the new Java-based command line interface that takes advantage of Oracle SQL Developer’s scripting engine. It delivers a modern command line interface that is backward compatible with SQL*Plus but also introduces new commands and features that have been missing for a long time. In this session, explore the new inline editing, query history, aliasing, output formatting, DDL generation, and scripting options that set SQLcl apart from its predecessor.”
Sunday, Sep 18, 8:00 a.m. – 8:45 a.m.| Moscone South—302
See you there!
My Data Model Checklist book is now available in Spanish – Just in time for #OOW14!
Posted: September 24, 2014 Filed under: Uncategorized Leave a commentExciting news!
I just got this email from Amazon:
Congratulations, your book “UNA LISTA DE VERIFICACIÓN PARA REALIZAR REVISIONES A LOS DISEÑOS DE MODELOS DE DATOS” is live in the Kindle Store and is currently enrolled in KDP Select. It is available for readers to purchase here.
If you are in Mexico, you can get the book here.
If you are in Spain, you can get it here.
Now, truth is I do NOT speak, read or write Spanish. But my good friend, and Oracle expert, Galo Balda does!
I am very grateful to Galo for putting in the effort to translate my little book so other data professionals around the world could read it in their native language.
You can (and should) follow Galo on Twitter, and on his personal blog in either English or Spanish.
BTW – Galo is speaking at OOW14 too…
View original post 36 more words
My Speaking Schedule for Oracle Open World 2014
Posted: August 27, 2014 Filed under: 12C, Open World, Oracle, Regular Expressions, Row Pattern Matching, SQL | Tags: 12C, Open World, Oracle, Regular Expressions, Row Pattern Matching, SQL Leave a commentA quick post to let you know about the two presentations that I’ll be doing at Oracle Open World 2014.
Session ID: UGF4482
Session Title: “Getting Started with SQL Pattern Matching in Oracle Database 12c“
Venue / Room: Moscone South – 301
Date and Time: 9/28/14, 13:30 – 14:15
Session ID: CON4493
Session Title: “Regular Expressions in Oracle Database 101”
Venue / Room: Moscone South – 303
Date and Time: 10/2/14, 13:15 – 14:00
As usual, you might have to check before the session to make sure the room has not changed.
I hope to see you there.
New in Oracle 12c: Querying an Associative Array in PL/SQL Programs
Posted: August 2, 2014 Filed under: 12C, PL/SQL | Tags: 12C, PL/SQL 9 CommentsI was aware that up to Oracle 11g, a PL/SQL program wasn’t allowed use an associative array in a SQL statement. This is what happens when I try to do it.
SQL> drop table test_array purge;
Table dropped.
SQL> create table test_array as
2 select level num_col from dual
3 connect by level <= 10;
Table created.
SQL> select * from test_array;
NUM_COL
----------
1
2
3
4
5
6
7
8
9
10
10 rows selected.
SQL> drop package PKG_TEST_ARRAY;
Package dropped.
SQL> create or replace package PKG_TEST_ARRAY as
2
3 type tab_num is table of number index by pls_integer;
4
5 end PKG_TEST_ARRAY;
6 /
Package created.
SQL> declare
2 my_array pkg_test_array.tab_num;
3 begin
4 for i in 1 .. 5 loop
5 my_array(i) := i*2;
6 end loop;
7
8 for i in (
9 select num_col from test_array
10 where num_col in (select * from table(my_array))
11 )
12 loop
13 dbms_output.put_line(i.num_col);
14 end loop;
15 end;
16 /
where num_col in (select * from table(my_array))
*
ERROR at line 10:
ORA-06550: line 10, column 51:
PLS-00382: expression is of wrong type
ORA-06550: line 10, column 45:
PL/SQL: ORA-22905: cannot access rows from a non-nested table item
ORA-06550: line 9, column 13:
PL/SQL: SQL Statement ignored
ORA-06550: line 13, column 26:
PLS-00364: loop index variable 'I' use is invalid
ORA-06550: line 13, column 5:
PL/SQL: Statement ignored
As you can see, the TABLE operator is expecting either a nested table or a varray.
The limitation has been removed in Oracle 12c. This is what happens now.
SQL> set serveroutput on
SQL>
SQL> drop table test_array purge;
Table dropped.
SQL> create table test_array as
2 select level num_col from dual
3 connect by level <= 10;
Table created.
SQL> select * from test_array;
NUM_COL
----------
1
2
3
4
5
6
7
8
9
10
10 rows selected.
SQL> drop package PKG_TEST_ARRAY;
Package dropped.
SQL> create or replace package PKG_TEST_ARRAY as
2
3 type tab_num is table of number index by pls_integer;
4
5 end PKG_TEST_ARRAY;
6 /
Package created.
SQL> declare
2 my_array pkg_test_array.tab_num;
3 begin
4 for i in 1 .. 5 loop
5 my_array(i) := i*2;
6 end loop;
7
8 for i in (
9 select num_col from test_array
10 where num_col in (select * from table(my_array))
11 )
12 loop
13 dbms_output.put_line(i.num_col);
14 end loop;
15 end;
16 /
2
4
6
8
10
PL/SQL procedure successfully completed.
Here’s another example using a slightly different query.
SQL> declare 2 my_array pkg_test_array.tab_num; 3 begin 4 for i in 1 .. 5 loop 5 my_array(i) := i*2; 6 end loop; 7 8 for i in ( 9 select a.num_col, b.column_value 10 from 11 test_array a, 12 table (my_array) b 13 where 14 a.num_col = b.column_value 15 ) 16 loop 17 dbms_output.put_line(i.num_col); 18 end loop; 19 end; 20 / 2 4 6 8 10 PL/SQL procedure successfully completed.
Very nice stuff.
Kscope14
Posted: July 21, 2014 Filed under: Kscope | Tags: Kscope Leave a comment
Photo by Nate Whitehill
It’s been a few weeks since I returned from another awesome Kscope conference and I just realized that I never wrote about it.
For me, it was the first time visiting Seattle and I really liked it even when I only managed to walk around the downtown area. I had some concerns about how the weather was going to be but everything worked out very well with clear skies, temperature in the mid 70’s and no rain!

The view from my hotel room.
The Sunday symposiums, the conference sessions and the hands-on labs provided really good content. I particularly enjoyed all the presentations delivered by Jonathan Lewis and Richard Foote.
My friend Amy Caldwell won the contest to have a dinner with ODTUG’s President Monty Latiolais and she was very kind to invite me as her guest. We had a good time talking about the past, present and future of ODTUG and it was enlightening and inspirational to say the least.
My presentation on row pattern matching went well but the attendance wasn’t the best mostly because I had to present on the last time slot when people were on party mode and ready to head to the EMP Museum for the big event. Nevertheless, I had attendees like Dominic Delmolino, Kim Berg Hansen, Alex Zaballa, Leighton Nelson, Joel Kallman and Patrick Wolf that had good questions about my topic.

Some comments on Social Media
As I said before, the big event took place at the EMP Museum and I believe everyone had a good time visiting the music and sci-fi exhibits and enjoying the food, drinks and music.

The EMP Museum
Next year, Kscope will take place on Hollywood, Florida. If you’re a Developer, DBA or an Architect working with Oracle products that’s where you want to be from June 21 – 25. I suggest you register and book your hotel room right away because it’s going to sell out really fast.
Hope to see you there!
SQL Developer’s Interface for GIT: Interacting with a GitHub Repository Part 2
Posted: April 16, 2014 Filed under: GIT, SQL Developer, Version Control | Tags: GIT, SQL Developer, Version Control 1 CommentIn this post I’m going to show to synchronize the remote and local repositories after an existing file in local gets modified. What I’ll do is modify the sp_test_git.pls file in our local repository and then push those changes to the remote repository (GitHub).
First, I proceed to open the sp_test_git.pls file using SQL Developer, add another dbms_output line to it and save it. The moment I save the file, the Pending Changes (Git) window gets updated to reflect the change and the icons in the toolbar get enabled.

Now I can include a comment and then add the file to the staging area by clicking on the Add button located on the Pending Changes (Git) window. Notice how the status changes from “Modified Not Staged” to “Modified Staged”.

What if I want to compare versions before doing a commit to the local repository? I just have to click on the Compare with Previous Version icon located on the Pending Changes (Git) window.

The panel on the left displays the version stored in the local repository and the panel on the right displays the version in the Staging Area.
The next step is to commit the changes to the local repository. For that I click on the Commit button located on the Pending Changes (Git) window and then I click on the OK button in the Commit window.

Now the Branch Compare window displays information telling that remote and local are out of sync.

So the final step is to sync up remote and local by pushing the changes to GitHub. For that I go to the main menu and click on Team -> Git -> Push to open the “Push to Git” wizard where I enter the URL for the remote repository, the user name and password to complete the operation. Now I go to GitHub to confirm the changes have been applied.

SQL Developer’s Interface for GIT: Interacting with a GitHub Repository Part 1
Posted: April 9, 2014 Filed under: GIT, SQL Developer, Version Control | Tags: GIT, SQL Developer, Version Control 10 CommentsIn my previous post, I showed how to clone a GitHub repository using SQL Developer. In this post I’m going to show to synchronize the remote and local repositories after remote gets modified.
Here I use GitHub to commit a file called sp_test_git.pls. You can create files by clicking on the icon the red arrow is pointing to.

The content of the file is a PL/SQL procedure that prints a message.

At this point, the remote repository and the local repository are out of sync. The first thing that you may want to do before modifying any repository, is to make sure that you have the most current version of it so that it includes the changes made by other developers. Let’s synchronize remote and local.
Make sure you open the Versions window. Go to the main menu click on Team -> Versions.

Open the Local branch and click on master, then go to main menu click on Team -> Git -> Fetch to open the “Fetch from Git” wizard. Fetching a repository copies changes from the remote repository into your local system, without modifying any of your current branches. Once you have fetched the changes, you can merge them into your branches or simply view them. We can see the changes on the Branch Compare window by going to the main menu click on Team -> Git -> Branch Compare.

Branch Compare is showing that sp_test_git.pls has been fetched from the remote master branch. We can right click on this entry and select compare to see the differences.

The window on the left displays the content of the fetched file and the window on right displays the content of the same file in the local repository. In this case the right windows is empty because this is a brand new file that doesn’t exist locally. Let’s accept the changes and merge them into the local repository. We go to the Branch Compare window, right click on the entry, select merge and click on the “Ok” button.

Now the changes should have been applied to the local repository.

We can go to the path where the local repository is located and confirm that sp_test_git.pls is there.
SQL Developer’s Interface for GIT: Cloning a GitHub Repository
Posted: April 2, 2014 Filed under: GIT, SQL Developer, Version Control | Tags: GIT, SQL Developer, Version Control 9 CommentsSQL Developer 4 provides an interface that allows us to interact with Git repositories. In this post, I’m going to show how to clone a GitHub (A web based hosting service for software development projects that uses the Git revision control system) repository.
First you need to sign up for a GitHub account. You can skip this step if you already have one.
Your account will give you access to public repositories that could be cloned but I suggest you create your own repository so that you can play with SQL Developer and see what the different options can do.
Once you have an account, click on the green button that says “New Repository”. It will take you to a screen like this:

Give your repository a name, decide if you want it to be public or private (you have to pay), click on the check box and then click on the green button. Now you should be taken to the main repository page.

Pay attention to the red arrow on the previous image. It points to a text box that contains the HTTPS clone URL that we’re going to use in SQL Developer to connect to GitHub.
Let’s go to SQL Developer and click on Team –> Git –> Clone… to open the “Clone from Git Wizard”. Click on the next button and you should see the screen that lets you enter the repository details:

Enter the repository name, the HTTPS clone URL, your GitHub user name and your password. Click on next to connect to the repository and see the remote branches that are available.

The master branch gets created by default for every new repository. Take the defaults on this screen and click on next to get to the screen where you specify the destination for your local Git repository.

Enter the path for the local repository and click on next. A summary screen is displayed and showing the options you chose. Click on finish to complete the setup.
How do we know if it worked? Go to the path of your local repository and it should contain the same structure as in the online repository.

On a next post I’ll show how to commit changes to the local repository and how to push them to GitHub.



